
How Does Googlebot Render Web Pages? Blogs Year
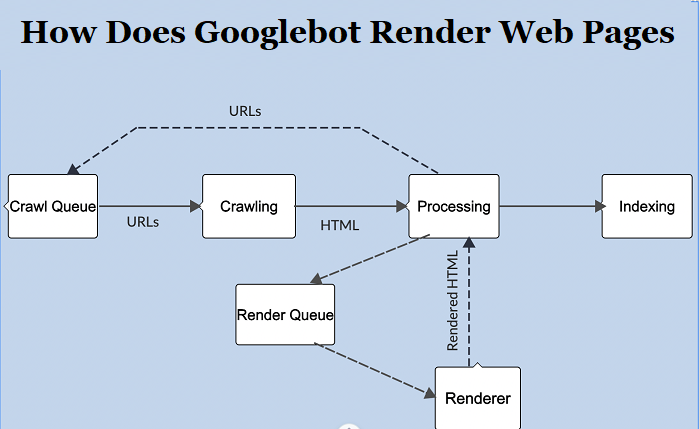
Googlebot rendering web pages is a crucial part of how Google understands and indexes the content of a website. The process involves both crawling and rendering, allowing Google to see the page similarly to how a user would. Here’s a breakdown of how Googlebot renders web pages:
Also Read:- SEO for SaaS: Increase Organic Search Performance for SaaS Businesses and Companies
1. Crawling:
Before rendering, Googlebot first crawls the web. It uses a list of known URLs and follows the links on these pages to discover new URLs. This process helps Googlebot find new pages and updates to existing ones.
2. Initial HTML Fetch:
Googlebot fetches the initial HTML of the page. At this stage, it doesn’t execute JavaScript or load CSS/images. It’s primarily looking for links and basic content.
3. Queue for Rendering:
After fetching the HTML, the page is queued for rendering. Due to the resource-intensive nature of rendering, especially with JavaScript-heavy sites, this doesn’t happen immediately. There can be a delay between when the HTML is fetched and when the page is rendered.
4. Rendering:
Googlebot uses a web rendering service (WRS) that’s based on the Chrome browser. This means Googlebot renders pages using a version of Chrome, allowing it to execute JavaScript, load CSS, and view pages as modern browsers do.
- JavaScript Execution: If a site relies on JavaScript to load content, Googlebot will execute the JavaScript during this rendering phase. This is crucial for websites that use JavaScript frameworks like React, Vue, or Angular.
- Loading Resources: Googlebot will also load necessary resources like CSS and images. However, it might not load all resources, especially if they require user interactions or if they’re disallowed in the robots.txt file.
5. Re-analyze the Page:
After rendering, Googlebot can see the fully-rendered content, including any content loaded via AJAX or other asynchronous methods. It will then re-analyze the page to understand its content, structure, and any other information that wasn’t available in the initial HTML.
6. Indexing:
Once the page is rendered and analyzed, it’s ready to be indexed. Google will store the content in its index, making it searchable for users.
Challenges & Considerations:
- Rendering Delays: As mentioned, rendering is resource-intensive. There can be significant delays between when Googlebot crawls the initial HTML and when it renders the page. This is known as the “crawl-render index” cycle.
- JavaScript Issues: If there are issues with the JavaScript, Googlebot might not see the content. It’s essential to ensure that critical content and links are accessible even without JavaScript.
- Resource Limitations: Googlebot doesn’t always load all resources. If certain resources are blocked (via robots.txt) or if they take too long to load, they might be skipped.
Conclusion:
Understanding how Googlebot renders pages is essential for modern SEO, especially with the rise of JavaScript frameworks and dynamic content. Webmasters should ensure their sites are easily crawlable and renderable, optimizing for both the initial HTML crawl and the subsequent rendering process.







